Tự cài đặt Nginx VPS server cho Newbie cân được 10.000 user

10.000 khách hàng mỗi giây trên WordPress – có thể!
Blog KAGG Design
Có thể “vắt kiệt” hiệu suất cao từ một trang WordPress không? Câu trả lời của chúng tôi là có! Trong bài viết này, chúng tôi hướng dẫn cách thiết lập một trang web WordPress được định cấu hình để duy trì tải cao lên đến 10.000 khách hàng mỗi giây, tương đương với 800 triệu lượt truy cập mỗi ngày.
Đầu tiên, chúng ta cần có máy chủ riêng ảo (VPS). Để thử nghiệm, chúng tôi đã sử dụng một VPS thuê từ DigitalOcean (giá hàng tháng 20 USD) với các thông số sau: 2GB bộ nhớ, 2 bộ xử lý, 40GB trên SSD. CentOS Linux phiên bản 7.3 đã được chọn làm hệ điều hành.
Văn bản dưới đây gần như là hướng dẫn từng bước cho các quản trị viên có kinh nghiệm. Chúng tôi sẽ chỉ cung cấp ở đây những thông số khác với những thông số mặc định và tăng hiệu suất máy chủ. Vậy thì cứ đi!
Cài đặt nginx
Đầu tiên, chúng tôi tạo một tệp kho lưu trữ yum cho nginx:touch /etc/yum.repos.d/nginx.repo
Chèn văn bản sau vào tệp này:12345[nginx]name=nginx repobaseurl=http://nginx.org/packages/OS/OSRELEASE/$basearch/gpgcheck=0enabled=1
Bạn phải thay thế “OS” thành “rhel” hoặc “centos” tùy thuộc vào phân phối được sử dụng và “OSRELEASE” thành “5”, “6” hoặc “7” cho các phiên bản 5.x, 6.x hoặc 7.x , trân trọng.
Bắt đầu cài đặt:yum -y install nginx
Chỉnh sửa nginx.conf01020304050607080910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970# Automatically setup number of processes, equal to number of processorsworker_processes auto;# In events section# epoll is an effective method of processing connectionsuse epoll;# Worker to accept all new connections at once (otherwise one by one)multi_accept on;# In http section# Switch off all logserror_log /var/log/nginx/error.log crit; # only critial error messagesaccess_log off;log_not_found off;# Switch off ability to show port number on redirectport_in_redirect off;# Allow more requests for keep-alive connectionkeepalive_requests 100;# Lower buffers to a resonable level# This allows to save memory at big number of requestsclient_body_buffer_size 10K;client_header_buffer_size 2k; # for WordPress, 2k may not be enoughclient_max_body_size 50m;large_client_header_buffers 2 4k;# Lower timeoutsclient_body_timeout 10;client_header_timeout 10;send_timeout 2;# Enable reset connections on timeoutreset_timedout_connection on;# Speed up tcptcp_nodelay on;tcp_nopush on;# Allow usage of system Linux function senfile() to speed up file transferssendfile on;# Turn on zipping of datagzip on;gzip_http_version 1.0;gzip_proxied any;gzip_min_length 1100;gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/svg+xml;gzip_disable msie6;gzip_vary on;# Turn on caching of open filesopen_file_cache max=10000 inactive=20s;open_file_cache_valid 30s;open_file_cache_min_uses 2;open_file_cache_errors on;# Set php timeoutfastcgi_read_timeout 300;# Connect php-fpm via socket - works faster than by tcpupstream php-fpm {# This must corespond to "listen" directive in php-fpm poolserver unix:/run/php-fpm/www.sock;}# Connect additional configuration filesinclude /etc/nginx/conf.d/*.conf;
Tạo tệp /etc/nginx/conf.d/servers.conf và ghi vào đây các phần máy chủ cho các trang web. Một ví dụ:01020304050607080910111213141516171819202122232425262728293031323334353637383940414243444546# Rewrite from httpserver {listen 80;server_name domain.com www.domain.com;rewrite ^(.*) https://$host$1 permanent;}# Process httpsserver {# Switch on http2 - speeds up processing (binary, multiplexing, etc.)listen 443 ssl http2;ssl_certificate /etc/nginx/ssl/domain.pem;ssl_certificate_key /etc/nginx/ssl/domain.key;server_name domain.com www.domain.com;root /var/www/domain;index index.php;# Process php fileslocation ~ \.php$ {fastcgi_buffers 8 256k;fastcgi_buffer_size 128k;fastcgi_intercept_errors on;include fastcgi_params;try_files $uri = 404;fastcgi_split_path_info ^(.+\.php)(/.+)$;fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;fastcgi_pass unix:/var/run/php-fpm.sock;fastcgi_index index.php;}# Cache all staticslocation ~* ^.+\.(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|rss|atom|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {expires max;add_header Cache-Control "public";}# Cache js and csslocation ~* ^.+\.(css|js)$ {expires 1y;add_header Cache-Control "max-age=31600000, public";}}
Bắt đầu nginx:systemctl start nginxsystemctl enable nginx
Cài đặt MySQL
yum install -y https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-community-server-5.7.18-1.el7.x86_64.rpmyum -y install mysql-community-server
Chỉnh sửa /etc/my.cnf
Dưới đây là nhóm thông số cho máy chủ có bộ nhớ 2GB. Đối với máy chủ bộ nhớ 1GB, bạn nên giảm kích thước bộ đệm đi một nửa, nhưng không đáng để chạm vào các thông số đó, có giá trị 64M trở xuống. Tất cả các tham số ở đây đều quan trọng, nhưng quan trọng nhất là “query_cache_type = ON”. Theo mặc định, bộ nhớ đệm các yêu cầu trong MySQL bị tắt! Không rõ lý do, có thể là tiết kiệm bộ nhớ. Tuy nhiên, với việc bật tham số này, việc truy cập cơ sở dữ liệu trở nên nhanh hơn nhiều, điều này có tác động ngay lập tức đến các trang quản trị của trang WordPress.0102030405060708091011121314151617181920212223242526max_connections = 64key_buffer_size = 32M# innodb_buffer_pool_chunk_size default value is 128Minnodb_buffer_pool_chunk_size=128M# When innodb_buffer_pool_size is less than 1024M,# innodb_buffer_pool_instances will be ajusted to 1 by MySQLinnodb_buffer_pool_instances = 1# innodb_buffer_pool_size must be equal to or a mulitple of# innodb_buffer_pool_chunk_size * innodb_buffer_pool_instancesinnodb_buffer_pool_size = 512Minnodb_flush_method = O_DIRECTinnodb_log_file_size = 512Minnodb_flush_log_at_trx_commit = 2thread_cache_size = 16query_cache_type = ONquery_cache_size = 128Mquery_cache_limit = 256Kquery_cache_min_res_unit = 2kmax_heap_table_size = 64Mtmp_table_size = 64M
Khởi đầu:systemctl start mysqldsystemctl enable mysqld
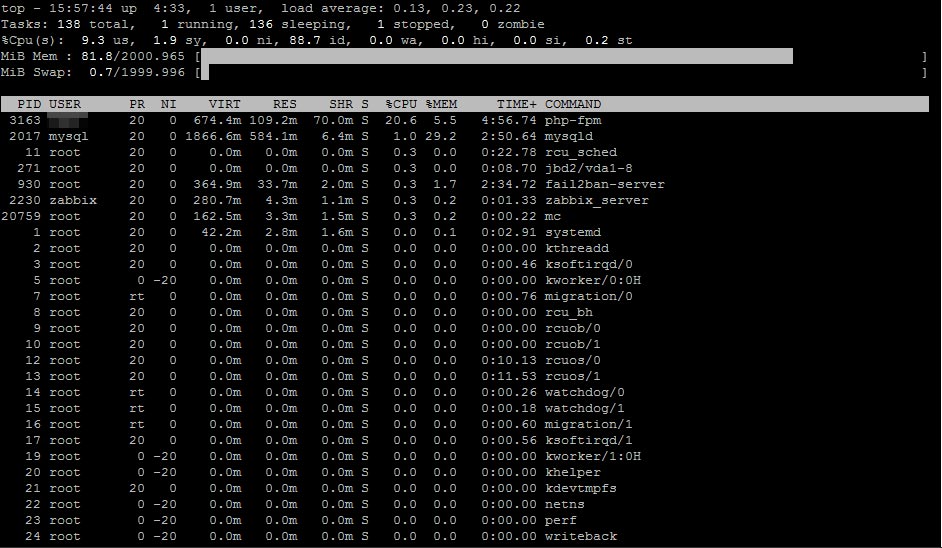
Nguyên tắc chính để tạo trang WordPress hiệu suất cao là như sau: mọi thứ phải nằm trong 75% bộ nhớ vật lý: nginx, mysql, php-fpm. Trong lệnh “top” của bảng điều khiển, chúng ta sẽ thấy rằng 20-25% bộ nhớ vật lý còn trống và hoán đổi không được sử dụng. Bộ nhớ dự phòng này sẽ rất hữu ích để khởi chạy nhiều quy trình php-fpm khi xử lý các trang web động.
Cài đặt php
Chắc chắn, chúng tôi chỉ quan tâm đến phiên bản 7, nhanh hơn gần 2 lần so với phiên bản trước đó – php5. Bản dựng tuyệt vời nằm trong kho lưu trữ webtatic. Ngoài ra, chúng tôi cần kho lưu trữ epel.
Tải về:rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpmrpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpmyum -y install php72wyum -y install php72w-fpmyum -y install php72w-gdyum -y install php72w-mbstringyum -y install php72w-mysqlndyum -y install php72w-opcacheyum -y install php72w-pear.noarchyum -y install php72w-pecl-imagickyum -y install php72w-pecl-apcuyum -y install php72w-pecl-redis
Hãy chú ý đến gói php72w-pecl-apcu, kết nối bộ đệm dữ liệu (APCu), ngoài bộ đệm đối tượng (OpCache) và với php72w-pecl-redis, kết nối máy chủ bộ đệm đối tượng Redis. WordPress hỗ trợ ACPu. Hỗ trợ Redis có sẵn với plugin Redis Object Cache .
Chỉnh sửa /etc/php.ini010203040506070809101112131415161718192021222324252627282930313233343536; This value should be increased on systems where PHP opens many filesrealpath_cache_size = 64M; Do not increase standard memory limit for process without certain need; Most of WordPress sites consume some 80 MBmemory_limit = 128M; And this is good to shrink to save memory allocated for buffers; Post size is rarely bigger than 64 MBpost_max_size = 64M; Usually size of downloads is not bigger than 50 MBupload_max_filesize = 50M; The following rule has to be used:; upload_max_filesize < post_max_size < memory_limit; And do not forget about OpCache tuning; Kill the processes holding locks on the cache immediatelyopcache.force_restart_timeout = 0; Save memory storing equal strings only once for all php-fpm processes; On 2GB server, it was impossible to set more than 8opcache.interned_strings_buffer = 8; Define how many PHP files, can be held in memory at once; On 2GB server, it was impossible to set more than 4000opcache.max_accelerated_files = 4000; Define how much memory opcache is consuming; On 2GB server, it was impossible to set more than 128opcache.memory_consumption = 128; Bitmask where bit raised means certain optimization pass is on; Full optimizationopcache.optimization_level = 0xFFFFFFFF
Chỉnh sửa /etc/php-fpm.d/www.conf01020304050607080910111213141516; Reduce number of child processes;pm.max_children = 50pm.max_children = 20;pm.start_servers = 5pm.start_servers = 8;pm.max_spare_servers = 35pm.max_spare_servers = 10; Kill processes after 10 seconds of inactivitypm.process_idle_timeout = 10s;; Number of requests of child process, after which in will be restarted; It is useful to prevent memory leakspm.max_requests = 500
Khởi đầu:systemctl restart php-fpmsystemctl enable php-fpm
Cài đặt Redis
Nó là đơn giản, không có cấu hình.yum -y install redissystemctl start redissystemctl enable redis
Cài đặt WordPress
Vâng, chúng tôi bỏ qua phần này là hiển nhiên.
Trên trang WordPress chắc chắn chúng ta phải cài đặt plugin WP Super Cache . Cài đặt tiêu chuẩn là OK. Plugin này làm gì? Ở lần đầu tiên truy cập vào một trang hoặc bài đăng trong WordPress, plugin tạo tệp .html có cùng tên và lưu nó. Trong những nỗ lực truy cập sau này, nó sẽ chặn việc thực thi WordPress và thay vì lặp lại các thế hệ trang, phân phối .html đã lưu từ bộ nhớ cache của chính nó. Rõ ràng là cơ chế này cải thiện triệt để hiệu suất trang web.
Kiểm tra
Tiếp tục đi?
Trên thực tế, có – chúng tôi có thể bắt đầu thử nghiệm. Như một con thỏ thử nghiệm đã được sử dụng trang web bạn đang đọc bây giờ và bản sao của nó tại test2.kagg.eu – tất cả đều giống nhau, nhưng không có https.
Như công cụ kiểm tra căng thẳng đã được chọn loader.io . Trên tài khoản miễn phí, dịch vụ web này cung cấp khả năng kiểm tra một trang web với tối đa 10.000 khách hàng mỗi giây. Nhưng chúng ta không cần nhiều hơn nữa, như chúng ta có thể thấy ở phần sau.
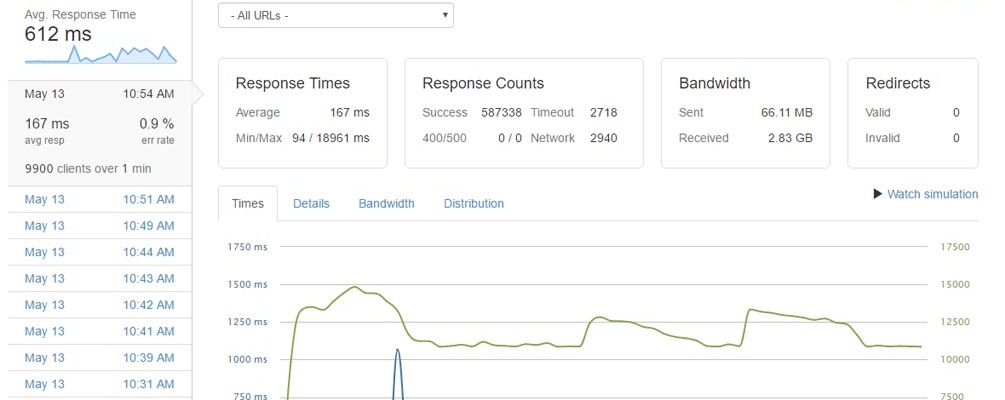
Kết quả đầu tiên ấn tượng – không có https trang web vẫn tồn tại 1.000 khách hàng mỗi giây. Kích thước trang, bao gồm cả hình ảnh, là 1,6 MB.
Microcaching
1.000 lượt truy cập mỗi giây không phải là xấu, nhưng chúng ta cần một thứ gì đó hơn thế nữa! Để làm gì? nginx có tính năng rất hữu ích là bộ nhớ đệm vi mô. Điều này có nghĩa là bộ nhớ đệm của các tệp và các tài nguyên khác trong một thời gian ngắn – từ vài giây đến vài phút. Khi các yêu cầu nhanh đến, người dùng tiếp theo sẽ nhận được dữ liệu từ bộ nhớ đệm vi mô, điều này làm giảm đáng kể thời gian phản hồi.
Chỉnh sửa /etc/nginx/nginx.conf – chèn một dòng trước khi kết thúc “bao gồm” trong mã trên:1fastcgi_cache_path /var/cache/nginx/fcgi levels=1:2 keys_zone=microcache:10m max_size=1024m inactive=1h;
Chỉnh sửa /etc/nginx/conf.d/servers.conf – trong phần “location ~ \ .php $ {” chèn:1234567fastcgi_cache microcache;fastcgi_cache_key $scheme$host$request_uri$request_method;fastcgi_cache_valid 200 301 302 30s;fastcgi_cache_use_stale updating error timeout invalid_header http_500;fastcgi_pass_header Set-Cookie;fastcgi_pass_header Cookie;fastcgi_ignore_headers Cache-Control Expires Set-Cookie;
Rõ ràng là khởi động lại nginx.
Kết quả thật tuyệt vời: chúng tôi tăng hiệu suất lên gấp 3 lần. Trang web cung cấp trang chủ có trọng lượng 1,6 MB trên http 3.000 lần mỗi giây! Thời gian phản hồi trung bình – 108 ms.
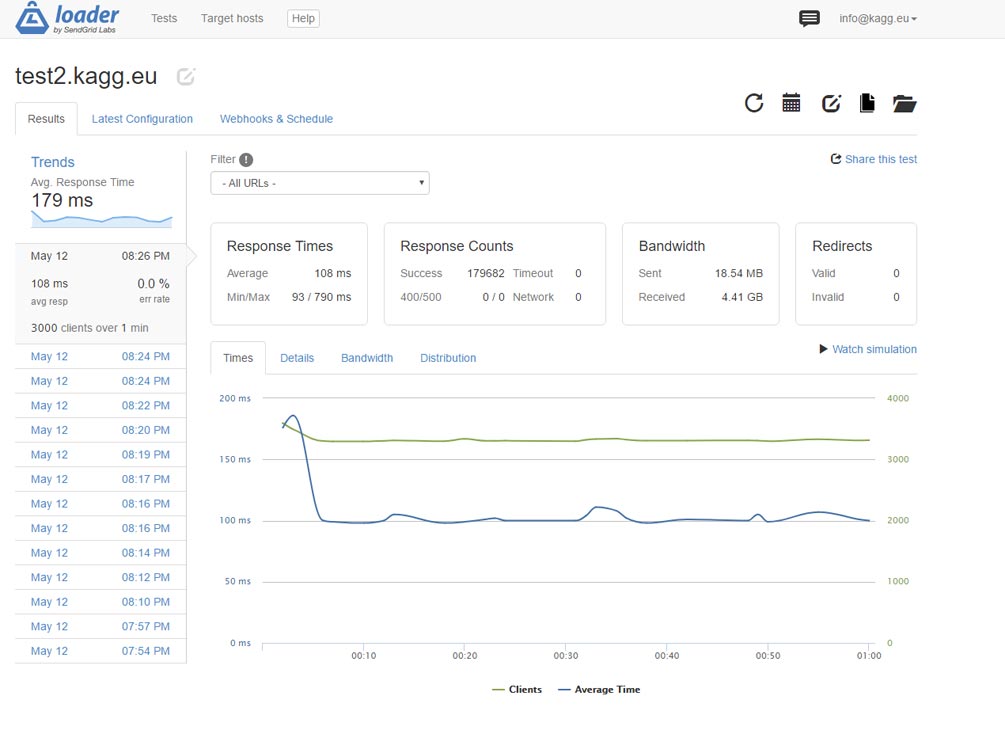
Kiểm tra trong mô hình khác: tăng tuyến tính các yêu cầu từ 0 đến 3.000 mỗi giây. Làm. Thời gian phản hồi trung bình – 210 ms.
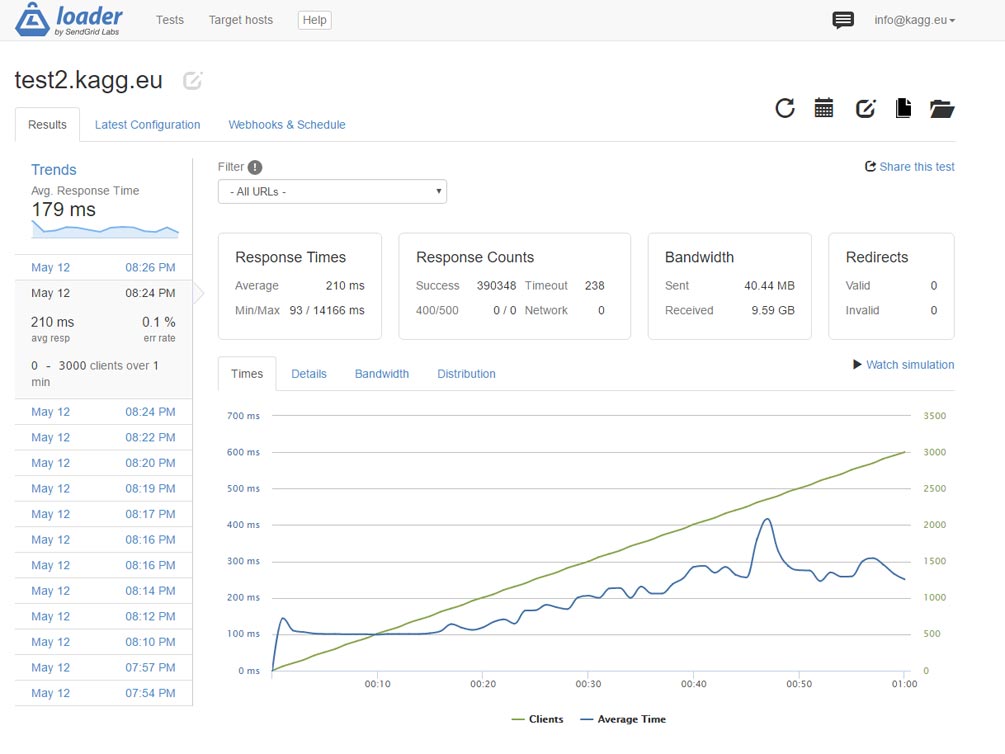
Luồng dữ liệu ở số lượng không đổi 3.000 khách hàng mỗi giây đạt 1 Gbit mỗi giây, ngay cả khi nén. Những gì chúng ta có thể thấy trên màn hình điều khiển Zabbix.
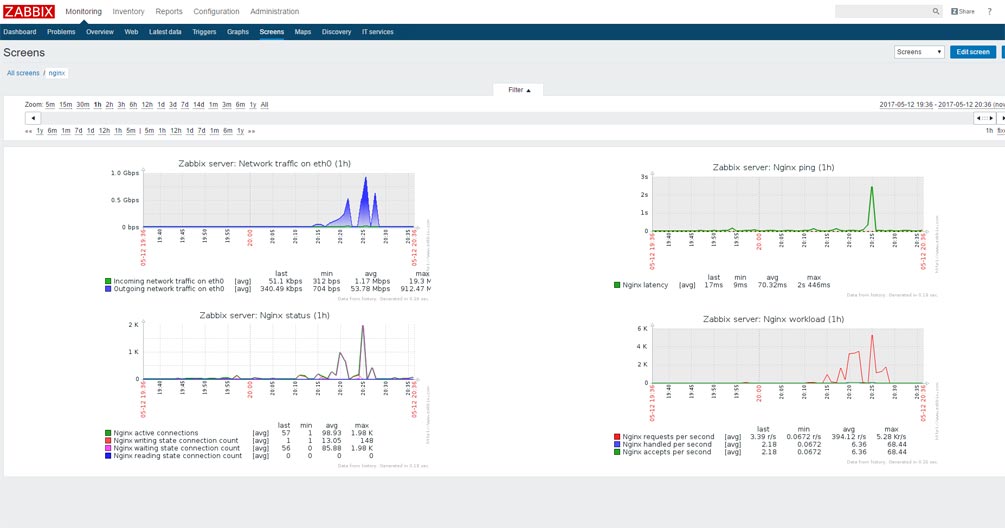
Nhân tiện, Zabbix chạy trên cùng một máy chủ thử nghiệm.
Và những gì với https?
Và với https, nó chậm hơn đáng kể so với mong đợi. Quá nhiều thao tác cho các cuộc đàm phán chính, băm, mã hóa, v.v … Thật là buồn cười khi thấy trong lệnh trên bảng điều khiển như hai nhân viên nginx ngốn hết 99% CPU của mỗi người :). Đây là kết quả – 1.000 kết nối mỗi giây:
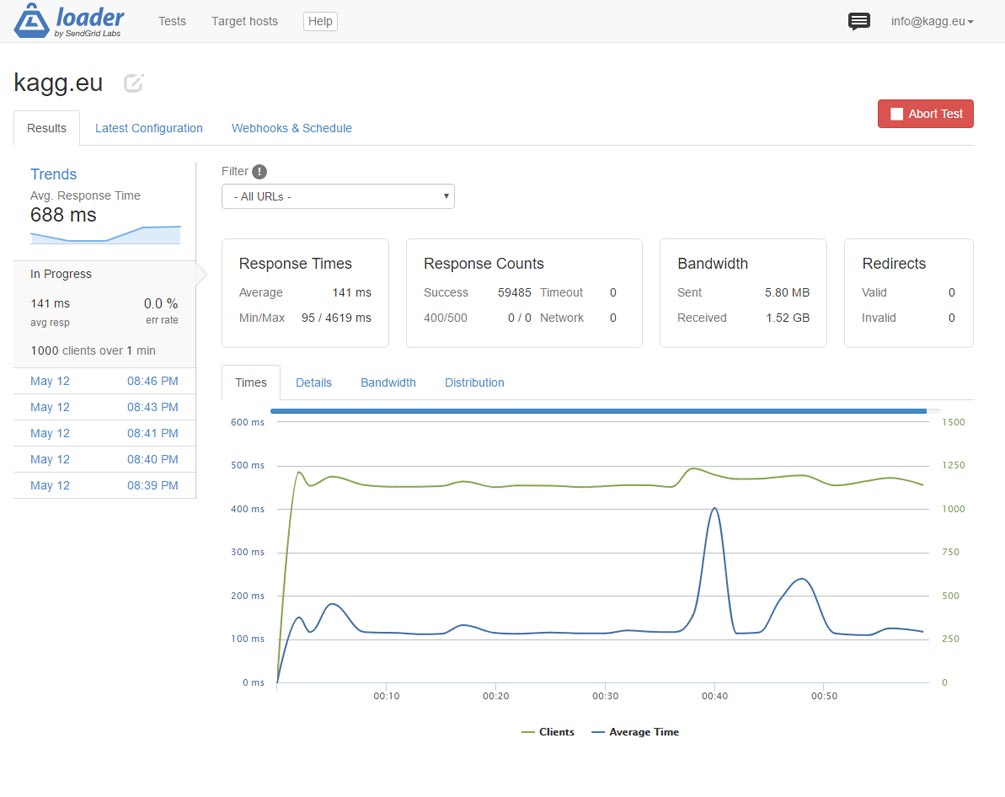
Kết quả không tệ, nhưng chúng ta có thể nhiều hơn thế!
Viết lại trong nginx
Chúng ta hãy suy nghĩ – điều gì sẽ xảy ra khi trang web được truy cập?
- nginx chấp nhận yêu cầu và thấy rằng index.php là cần thiết
- nginx khởi động php-fpm (không nhanh chút nào)
- WordPress bắt đầu hoạt động
- Lúc đầu, plugin WP Super Cache gặp và trượt đã được lưu .html thay vì tạo trang dài vô hạn (theo các điều kiện thời gian này)
Không có gì là xấu, nhưng: chúng ta cần bắt đầu php-fpm, sau đó thực thi một số mã php, để phản hồi với .html đã lưu.
Có một giải pháp làm thế nào để tiếp tục mà không có php nào cả. Hãy để chúng tôi viết lại trên nginx ngay lập tức.
Chỉnh sửa lại /etc/nginx/conf.d/servers.conf – và sau “index index.php;” chèn dòng:1include snippets/wp-supercache.conf;
Tạo thư mục / etc / nginx / snippets và tập tin wp-supercache.conf trong đó với nội dung sau:01020304050607080910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182# WP Super Cache rules.set $cache true;# POST requests and urls with a query string should always go to PHPif ($request_method = POST) {set $cache false;}if ($query_string != "") {set $cache false;}# Don't cache uris containing the following segmentsif ($request_uri ~* "(/wp-admin/|/xmlrpc.php|/wp-(app|cron|login|register|mail).php|wp-.*.php|/feed/|index.php|wp-comments-popup.php|wp-links-opml.php|wp-locations.php|sitemap(_index)?.xml|[a-z0-9_-]+-sitemap([0-9]+)?.xml)") {set $cache false;}# Don't use the cache for logged-in users or recent commentersif ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+|wp-postpass|wordpress_logged_in") {set $cache false;}# Set the cache fileset $cachefile "/wp-content/cache/supercache/$http_host${request_uri}index.html";set $gzipcachefile "/wp-content/cache/supercache/$http_host${request_uri}index.html.gz";if ($https ~* "on") {set $cachefile "/wp-content/cache/supercache/$http_host${request_uri}index-https.html";set $gzipcachefile "/wp-content/cache/supercache/$http_host${request_uri}index-https.html.gz";}set $exists 'not exists';if (-f $document_root$cachefile) {set $exists 'exists';}set $gzipexists 'not exists';if (-f $document_root$gzipcachefile) {set $gzipexists 'exists';}if ($cache = false) {set $cachefile "";set $gzipcachefile "";}# Add cache file debug info as header#add_header X-HTTP-Host $http_host;add_header X-Cache-File $cachefile;add_header X-Cache-File-Exists $exists;add_header X-GZip-Cache-File $gzipcachefile;add_header X-GZip-Cache-File-Exists $gzipexists;#add_header X-Allow $allow;#add_header X-HTTP-X-Forwarded-For $http_x_forwarded_for;#add_header X-Real-IP $real_ip;# Try in the following order: (1) gzipped cachefile, (2) cachefile, (3) normal url, (4) phplocation / {try_files @gzipcachefile @cachefile $uri $uri/ /index.php?$args;}# Set expiration for gzipcachefilelocation @gzipcachefile {expires 43200;add_header Cache-Control "max-age=43200, public";try_files $gzipcachefile =404;}# Set expiration for cachefilelocation @cachefile {expires 43200;add_header Cache-Control "max-age=43200, public";try_files $cachefile =404;}
Thực hiện hướng dẫn này, nginx sẽ tự tìm kiếm, nếu có .html có sẵn (hoặc nén .html.gz) trong các thư mục plugin WP Super Cache và nếu .html tồn tại, sẽ thực hiện mà không cần khởi động bất kỳ php-fpm nào.
Khởi động lại nginx, bắt đầu kiểm tra và xem lệnh trên bảng điều khiển. Và – thật là một điều kỳ diệu – không có quy trình php-fpm nào đang bắt đầu, khi trước đây chúng ta đã thấy một cặp hàng chục. Chỉ có nginx hoạt động bởi hai trong số các công nhân của riêng mình.
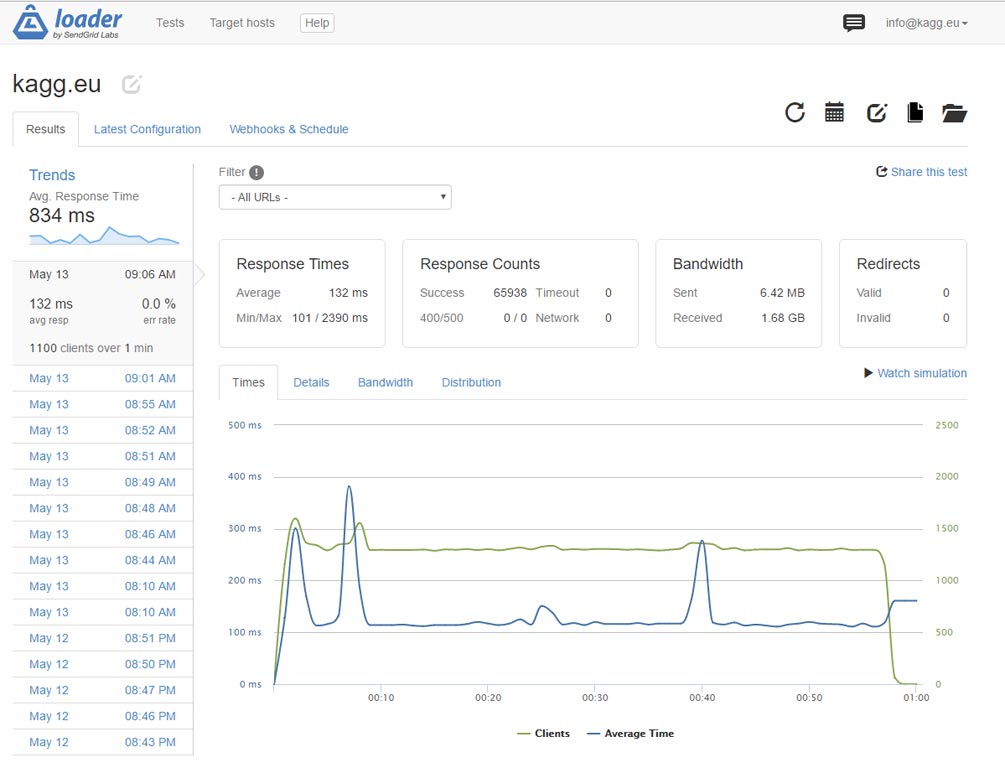
Chúng ta có gì trong kết quả? Thay vì 3.000 lần mỗi giây, máy chủ có thể quay lại trang chủ mà không cần https 7.500 lần mỗi giây! Hãy nhớ rằng, dung lượng của trang là 1,6 MB. Luồng dữ liệu là 2 Gigabit mỗi giây và có vẻ như chúng tôi bị giới hạn bởi băng thông máy chủ DigitalOcean.
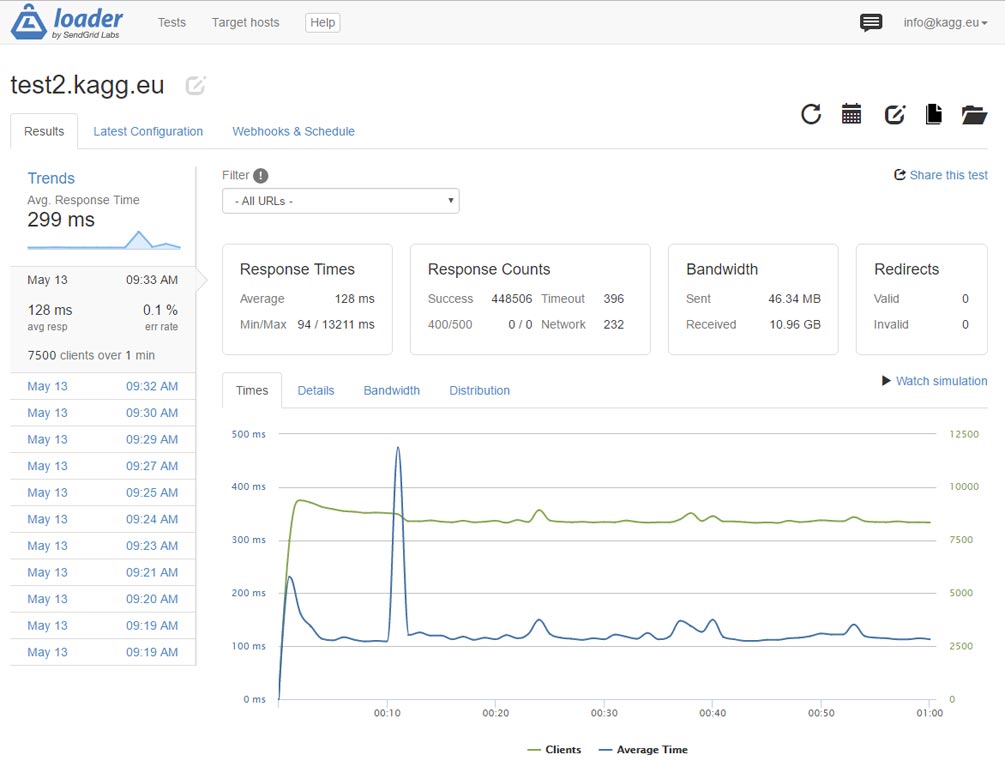
Và, điều gì sẽ xảy ra nếu để kiểm tra phản hồi của một trang nhỏ, giả sử / các địa chỉ liên hệ trên cùng một trang web?
Ở đây có lẽ chúng tôi đã đạt đến giới hạn máy chủ. Tuy nhiên, kết quả từ tiêu đề của bài viết này: 10.000 khách hàng mỗi giây! Hãy nhớ rằng – 10.000 lượt truy cập trang mỗi giây trên một trang WordPress thực – với các plugin được cài đặt, đẹp (nhưng không phải là một chủ đề nhẹ), v.v.
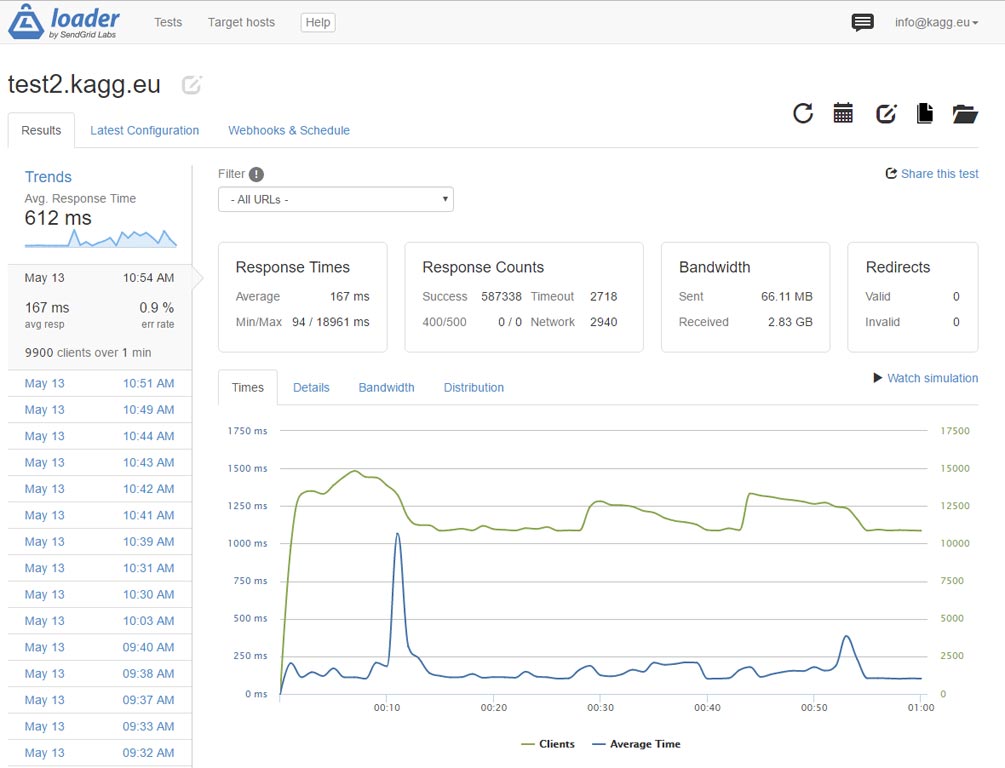
Kịch bản tăng tải cũng hoạt động.
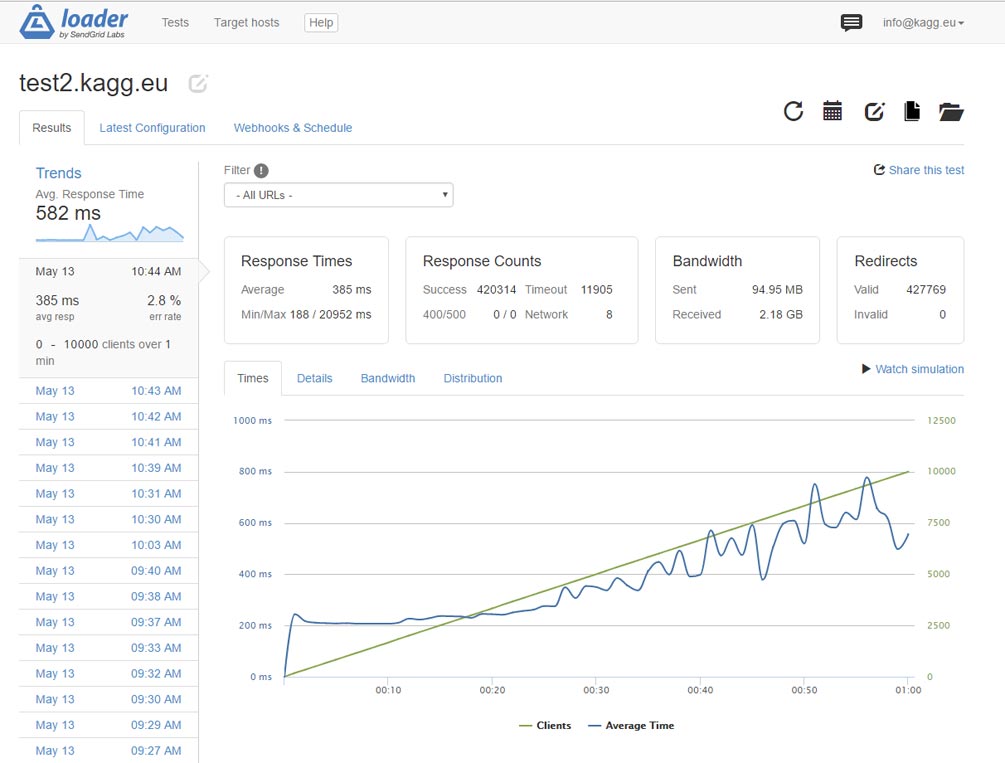
Thử nghiệm với https trong cấu hình này cho thấy hiệu suất không tăng đáng kể – lên đến 1.100 máy khách mỗi giây. Tất cả thời gian của CPU dường như được trả cho việc giải mật mã…
Tóm lược
Ở đây, chúng tôi đã chỉ ra rằng một trang WordPress chuẩn với cấu hình máy chủ và bộ nhớ đệm phù hợp có thể trả về không dưới 10.000 trang mỗi giây qua http. Trong suốt 24 giờ, một trang web như vậy có thể chịu được 800 triệu lượt truy cập đáng kinh ngạc.
Trên https, cùng một trang web có thể trả về không ít hơn 1.100 trang mỗi giây.
Các phương tiện và phương pháp được sử dụng để đạt được kết quả:
- Máy chủ ảo (VPS) trên DigitalOcean: bộ nhớ 2 GB, 2 bộ xử lý, 40 GB SSD, 20 USD mỗi tháng
- CentOS 7.3 64-bit
- Phiên bản mới nhất của nginx, php7, mysql
- Plugin WP Super Cache
- Microcaching trong nginx
- Đoạn trích đầy đủ của khởi động php thậm chí để hiển thị các trang được lưu trong bộ nhớ cache –
bằng cách viết lại trong nginx
Connection Pooling
Chúng tôi có xu hướng dựa vào các giải pháp bộ nhớ đệm để cải thiện hiệu suất cơ sở dữ liệu. Lưu vào bộ nhớ đệm các truy vấn được truy cập thường xuyên trong bộ nhớ hoặc qua cơ sở dữ liệu có thể tối ưu hóa hiệu suất ghi / đọc và giảm độ trễ mạng, đặc biệt đối với các ứng dụng có khối lượng công việc nặng, chẳng hạn như dịch vụ trò chơi và cổng Hỏi & Đáp. Nhưng bạn có thể cải thiện hiệu suất hơn nữa bằng cách gộp các kết nối của người dùng vào một cơ sở dữ liệu.
Người dùng ứng dụng khách cần tạo kết nối với dịch vụ web trước khi họ có thể thực hiện các hoạt động CRUD. Hầu hết các dịch vụ web được hỗ trợ bởi các máy chủ cơ sở dữ liệu quan hệ như Postgres hoặc MySQL. Với PostgreSQL, mỗi kết nối mới có thể chiếm tới 1,3MB bộ nhớ. Trong môi trường sản xuất mà chúng tôi mong đợi nhận được hàng nghìn hoặc hàng triệu kết nối đồng thời đến dịch vụ phụ trợ, điều này có thể nhanh chóng vượt quá tài nguyên bộ nhớ của bạn (hoặc nếu bạn có một đám mây có thể mở rộng, nó có thể rất tốn kém).
Bởi vì mỗi khi khách hàng cố gắng truy cập vào một dịch vụ phụ trợ, nó yêu cầu tài nguyên hệ điều hành để tạo, duy trì và đóng các kết nối với kho dữ liệu. Điều này tạo ra một lượng lớn chi phí làm cho hiệu suất cơ sở dữ liệu xấu đi.
Người tiêu dùng dịch vụ của bạn mong đợi thời gian phản hồi nhanh chóng. Nếu hiệu suất đó kém đi, nó có thể dẫn đến trải nghiệm người dùng kém, thất thoát doanh thu và thậm chí là thời gian ngừng hoạt động ngoài dự kiến. Nếu bạn để lộ dịch vụ phụ trợ của mình dưới dạng một API, việc làm chậm và lỗi lặp đi lặp lại có thể gây ra sự cố xếp tầng và khiến bạn mất khách hàng.
Thay vì mở và đóng các kết nối cho mọi yêu cầu, gộp kết nối sử dụng một bộ nhớ cache các kết nối cơ sở dữ liệu có thể được sử dụng lại khi các yêu cầu trong tương lai tới cơ sở dữ liệu được yêu cầu. Nó cho phép cơ sở dữ liệu của bạn mở rộng quy mô hiệu quả khi dữ liệu được lưu trữ ở đó và số lượng khách hàng truy cập nó ngày càng tăng. Lưu lượng truy cập không bao giờ cố định, vì vậy việc gộp chung có thể quản lý tốt hơn các đỉnh lưu lượng mà không gây ra tình trạng ngừng hoạt động. Cơ sở dữ liệu sản xuất của bạn không nên là điểm nghẽn của bạn.
Trong bài viết này, chúng ta sẽ khám phá cách chúng ta có thể sử dụng phần mềm trung gian gộp kết nối như pgpool và pgbouncer để giảm chi phí và độ trễ mạng. Với mục đích minh họa, tôi sẽ sử dụng pgpool-II và pgbouncer để giải thích các khái niệm về gộp kết nối và so sánh cái nào hiệu quả hơn trong việc gộp các kết nối vì một số trình đánh cắp kết nối thậm chí có thể ảnh hưởng đến hiệu suất cơ sở dữ liệu.
Chúng ta sẽ xem xét cách sử dụng pgbench để đánh giá cơ sở dữ liệu Postgres vì nó là công cụ tiêu chuẩn được cung cấp bởi PostgreSQL.
Phần cứng khác nhau cung cấp các kết quả đo điểm chuẩn khác nhau dựa trên kế hoạch bạn đặt. Đối với các bài kiểm tra bên dưới, tôi đang sử dụng các thông số kỹ thuật này.
Thông số kỹ thuật của máy thử nghiệm của tôi:
- Máy chủ Linode: Ubuntu 16 – 64 bit (Máy ảo)
- Postgres phiên bản 9.5
- Bộ nhớ: 2GB Kích thước cơ sở dữ liệu: 800MB
- Bộ nhớ: 2GB
Ngoài ra, điều quan trọng là phải cách ly máy chủ cơ sở dữ liệu Postgres khỏi các khuôn khổ khác như logstash shipper và các máy chủ khác để thu thập số liệu hiệu suất vì hầu hết các thành phần này tiêu tốn nhiều bộ nhớ hơn và sẽ ảnh hưởng đến kết quả kiểm tra.
Tạo kết nối tổng hợp
Kết nối với dịch vụ phụ trợ là một hoạt động tốn kém, vì nó bao gồm các bước sau:
- Mở kết nối với cơ sở dữ liệu bằng trình điều khiển cơ sở dữ liệu.
- Mở ổ cắm TCP cho các hoạt động CRUD
- Thực hiện các hoạt động CRUD trên ổ cắm.
- Đóng kết nối.
- Đóng ổ cắm.
Trong môi trường sản xuất mà chúng tôi mong đợi hàng nghìn kết nối mở và đóng đồng thời từ các máy khách, việc thực hiện các bước trên cho mọi kết nối đơn lẻ có thể khiến cơ sở dữ liệu hoạt động kém.
Chúng tôi có thể giải quyết vấn đề này bằng cách tổng hợp các kết nối từ các máy khách. Thay vì tạo kết nối mới với mọi yêu cầu, trình đánh cắp kết nối sử dụng lại một số kết nối hiện có. Vì vậy, không cần phải thực hiện nhiều chuyến đi cơ sở dữ liệu đầy đủ tốn kém bằng cách mở và đóng các kết nối đến dịch vụ phụ trợ. Nó ngăn chặn chi phí tạo kết nối mới đến cơ sở dữ liệu mỗi khi có yêu cầu kết nối cơ sở dữ liệu có cùng thuộc tính (ví dụ: tên, cơ sở dữ liệu, phiên bản giao thức).
Phần mềm trung gian gộp như pgbouncer đi kèm với trình quản lý nhóm. Thông thường, trình quản lý nhóm kết nối duy trì một nhóm các kết nối cơ sở dữ liệu mở. Bạn không thể kết nối pool mà không có người quản lý pool.
Một nhóm chứa hai loại kết nối:
- Kết nối đang hoạt động : Ứng dụng đang được sử dụng.
- Kết nối không hoạt động: Có sẵn để sử dụng bởi ứng dụng.
Khi một yêu cầu mới để truy cập dữ liệu từ dịch vụ phụ trợ đến, người quản lý nhóm sẽ kiểm tra xem nhóm có chứa bất kỳ kết nối chưa sử dụng nào không và trả về một kết nối nếu có. Nếu tất cả các kết nối trong pool đang hoạt động, thì một kết nối mới sẽ được tạo và thêm vào pool bởi người quản lý pool. Khi hồ bơi đạt đến kích thước tối đa, tất cả các kết nối mới sẽ được xếp hàng đợi cho đến khi có kết nối trong hồ bơi.
Mặc dù hầu hết các cơ sở dữ liệu không có hệ thống gộp kết nối tích hợp sẵn, nhưng có những giải pháp phần mềm trung gian mà chúng ta có thể sử dụng để gộp các kết nối từ các máy khách.
Đối với máy chủ cơ sở dữ liệu PostgreSQL, cả pgbouncer và pgpool-II đều có thể đóng vai trò là giao diện gộp giữa dịch vụ web và cơ sở dữ liệu Postgres. Cả hai tiện ích đều sử dụng cùng một logic để gộp các kết nối từ các máy khách.
pgpool-II cung cấp nhiều tính năng hơn ngoài tính năng gộp kết nối, chẳng hạn như tính năng sao chép, cân bằng tải và truy vấn song song.
Làm cách nào để bạn thêm gộp kết nối? Nó có đơn giản như cài đặt các tiện ích?
Hai cách để tích hợp trình gộp kết nối
Có hai cách để triển khai gộp kết nối cho ứng dụng PostgreSQL:
- Là một dịch vụ bên ngoài hoặc phần mềm trung gian như pgbouncer
Các trình phân tích kết nối như pgbouncer và pgpool-II có thể được sử dụng để gộp các kết nối từ máy khách đến cơ sở dữ liệu PostgreSQL. Bộ gộp kết nối nằm giữa ứng dụng và máy chủ cơ sở dữ liệu. Pgbouncer hoặc pgpool-II có thể được cấu hình theo cách để chuyển tiếp các yêu cầu từ ứng dụng đến máy chủ cơ sở dữ liệu.
- Thư viện phía máy khách như c3p0
Có các thư viện tồn tại như c3p0 mở rộng chức năng trình điều khiển cơ sở dữ liệu để bao gồm hỗ trợ gộp kết nối.
Tuy nhiên, cách tốt nhất để thực hiện gộp kết nối cho các ứng dụng là sử dụng dịch vụ bên ngoài hoặc phần mềm trung gian vì nó dễ thiết lập và quản lý hơn. Ngoài ra, phần mềm trung gian bên ngoài như pgpool2 cung cấp các tính năng khác như cân bằng tải ngoài kết nối gộp.
Bây giờ chúng ta hãy xem xét sâu hơn điều gì sẽ xảy ra khi một dịch vụ phụ trợ kết nối với cơ sở dữ liệu Postgres, cả khi có và không có gộp chung.
Chia tỷ lệ hiệu suất cơ sở dữ liệu mà không cần tổng hợp kết nối
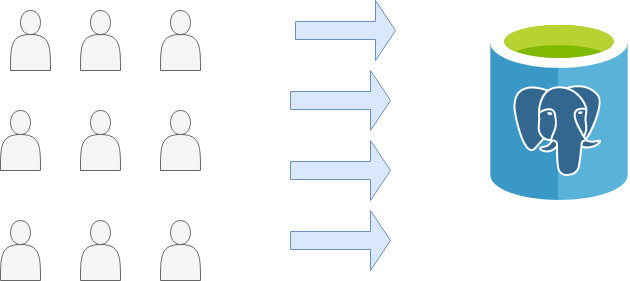
Chúng tôi không cần một bộ gộp kết nối để kết nối với một dịch vụ phụ trợ. Chúng tôi có thể kết nối trực tiếp với cơ sở dữ liệu Postgres. Để kiểm tra mất bao lâu để thực thi các kết nối đồng thời đến cơ sở dữ liệu mà không có bộ gộp kết nối, chúng tôi sẽ sử dụng pgbench để đánh giá các kết nối đến cơ sở dữ liệu Postgres.
Pgbench dựa trên TPC-B . TPC-B đo lường thông lượng về số lượng giao dịch mỗi giây mà hệ thống có thể thực hiện. Pgbench thực hiện năm lệnh SELECT , INSERT và UPDATE cho mỗi giao dịch.
Dựa trên các giao dịch giống TPC-B, pgbench chạy cùng một chuỗi lệnh SQL lặp đi lặp lại trong nhiều phiên cơ sở dữ liệu đồng thời và tính toán tốc độ giao dịch trung bình.
Trước khi chúng tôi chạy pgbench, chúng ta cần phải khởi tạo nó với các lệnh sau để tạo pgbench_history, pgbench_branches, pgbench_tellers, và pgbench_accountsbảng. Pgbench sử dụng các bảng sau để chạy các giao dịch để đo điểm chuẩn.
pgbench -i -s 50 database_name
Sau đó, tôi thực hiện lệnh bên dưới để kiểm tra cơ sở dữ liệu với 150 máy khách
pgbench -c 10 -j 2 -t 10000 database_name
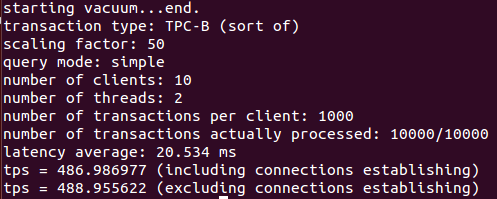
Như bạn thấy, trong thử nghiệm cơ bản ban đầu của chúng tôi, tôi đã hướng dẫn pgbench thực thi với mười phiên khách hàng khác nhau. Mỗi phiên khách hàng sẽ thực hiện 10.000 giao dịch.
Từ những kết quả này, có vẻ như thử nghiệm cơ bản ban đầu của chúng tôi là 486 giao dịch mỗi giây.
Hãy xem cách chúng ta có thể sử dụng các trình đánh cắp kết nối như pgbouncer và pgpool để tăng thông lượng giao dịch và tránh lỗi ‘Xin lỗi !, đã có quá nhiều khách hàng’ .
Mở rộng hiệu suất cơ sở dữ liệu với pgbouncer
Hãy xem cách chúng ta có thể sử dụng pgbouncer để tăng thông lượng giao dịch.
Pgbouncer có thể được cài đặt trên hầu hết các bản phân phối Linux. Bạn có thể kiểm tra tại đây cách thiết lập pgbouncer. Ngoài ra, bạn có thể cài đặt pgbouncer bằng cách sử dụng trình quản lý gói như apt-gethoặc yum.
Nếu bạn cảm thấy khó xác thực khách hàng bằng pgbouncer, bạn có thể kiểm tra GitHub để biết cách thực hiện.
Pgbouncer đi kèm với ba loại gộp:
- Nhóm phiên : Một trong các kết nối trong nhóm được gán cho một máy khách cho đến khi đạt đến thời gian chờ.
- Tổng hợp giao dịch : Tương tự như bỏ phiếu phiên, nó nhận được kết nối từ nhóm. Nó giữ nó cho đến khi giao dịch được thực hiện. Nếu cùng một khách hàng muốn chạy một giao dịch khác, nó phải đợi cho đến khi nó được gán cho một giao dịch khác.
- Nhóm câu lệnh : Kết nối được trả về nhóm ngay sau khi hoàn thành truy vấn đầu tiên.
Chúng tôi sẽ sử dụng chế độ gộp giao dịch. Bên trong pgbouncer.initệp, tôi đã sửa đổi tham số sau:
max_client_conn = 100
Các max_client_conntham số định nghĩa bao nhiêu kết nối khách hàng để pgbouncer (thay vì Postgres) được cho phép.
default_pool_size = 25
Các default_pool_sizetham số định nghĩa bao nhiêu kết nối máy chủ để cho phép mỗi cặp user / cơ sở dữ liệu.
reserve_pool_size = 5
Các tham số định nghĩa bao nhiêu kết nối thêm được phép vào hồ bơi. reserve_pool_size
Như trong thử nghiệm trước, tôi đã thực thi pgbench với mười phiên khách khác nhau. Mỗi khách hàng thực hiện 1000 giao dịch như hình bên dưới.
pgbench -c 10 -p -j 2 -t 1000 database_name
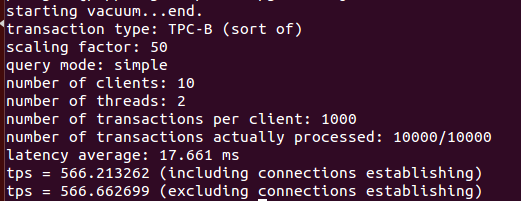
Như bạn thấy, thông lượng giao dịch tăng từ 486 giao dịch mỗi giây lên 566 giao dịch mỗi giây. Với sự trợ giúp của pgbouncer, thông lượng giao dịch được cải thiện khoảng 60%.
Bây giờ, hãy xem cách chúng ta có thể tăng thông lượng giao dịch với pgpool-II vì nó đi kèm với các tính năng tổng hợp kết nối.
Không giống như pgbouncer, pgpool-II cung cấp các tính năng ngoài tính năng tổng hợp kết nối. Các tài liệu cung cấp thông tin chi tiết về pgpool-II có và làm thế nào để thiết lập nó từ nguồn hoặc qua một người quản lý gói
Tôi đã thay đổi các tham số sau trong pgpool.conftệp để làm cho nó định tuyến các kết nối máy khách từ pgpool2 đến máy chủ cơ sở dữ liệu Postgres.
connection_cache = on listening_addresses = 'postgres_database_name' ' port = 5432
Đặt connection_cache tham số để onkích hoạt khả năng gộp pgpool2.
Giống như thử nghiệm trước, pgbench đã thực thi mười phiên khách hàng khác nhau. Mỗi máy khách thực hiện 1000 giao dịch đến máy chủ cơ sở dữ liệu Postgres. Do đó, chúng tôi dự kiến có tổng cộng 10.000 giao dịch từ tất cả các khách hàng.
gbench -p 9999 -c 10 -C -t 1000 postgres_database

Theo cách tương tự, chúng tôi đã tăng thông lượng giao dịch với pgbouncer, có vẻ như pgpool2 cũng đã tăng thông lượng giao dịch lên 75% so với thử nghiệm ban đầu.
Pgbouncer thực hiện tổng hợp kết nối ‘ra khỏi hộp’ mà không cần tinh chỉnh các thông số trong khi pgpool2 cho phép bạn tinh chỉnh các thông số để tăng cường tổng hợp kết nối.
Chọn một pooler kết nối: pgpool-II hay pgbouncer?
Có một số yếu tố cần xem xét khi chọn một trình gộp kết nối để sử dụng. Mặc dù pgbouncer và pgpool-II là những giải pháp tuyệt vời để tổng hợp kết nối, nhưng mỗi công cụ đều có điểm mạnh và điểm yếu.
Tiêu thụ bộ nhớ / tài nguyên
Nếu bạn quan tâm đến một trình gộp kết nối nhẹ cho dịch vụ phụ trợ của mình, thì pgbouncer là công cụ phù hợp với bạn. Không giống như pgpool-II, theo mặc định cho phép chia nhỏ 32 quy trình con, pgbouncer chỉ sử dụng một quy trình. Do đó pgbouncer tiêu tốn ít bộ nhớ hơn pgpool2.
Truyền trực tuyến sao chép
Ngoài việc gộp các kết nối, bạn cũng có thể quản lý cụm Postgres của mình với tính năng sao chép trực tuyến bằng pgpool-II. Sao chép luồng sao chép dữ liệu từ một nút chính sang một nút phụ. Pgpool-II hỗ trợ sao chép luồng Postgres, trong khi pgbouncer thì không. Đó là cách tốt nhất để đạt được tính khả dụng cao và ngăn ngừa mất mát dữ liệu.
Quản lý mật khẩu tập trung
Trong môi trường sản xuất mà bạn mong đợi nhiều máy khách / ứng dụng kết nối đồng thời với cơ sở dữ liệu thông qua bộ gộp kết nối, bạn cần sử dụng hệ thống quản lý mật khẩu tập trung để quản lý thông tin đăng nhập của khách hàng.
Bạn có thể sử dụng auth_query trong pgbouncer để tải thông tin đăng nhập của khách hàng từ cơ sở dữ liệu thay vì lưu trữ thông tin đăng nhập của khách hàng trong một userlist.txttệp và so sánh thông tin xác thực từ chuỗi kết nối với userlist.txttệp.
Cân bằng tải và tính sẵn sàng cao
Cuối cùng, nếu bạn muốn thêm tính năng cân bằng tải và tính khả dụng cao cho các kết nối được gộp chung của mình, thì pgpool2 là công cụ phù hợp để sử dụng. pgpool2 hỗ trợ tính khả dụng cao của Postgres thông qua các quy trình cơ quan giám sát tích hợp sẵn. Quá trình con pgpool2 này giám sát sức khỏe của các nút pgpool2 tham gia vào cụm cơ quan giám sát cũng như phối hợp giữa nhiều nút pgpool2.
Phần kết luận
Hiệu suất cơ sở dữ liệu có thể được cải thiện ngoài việc tổng hợp kết nối. Nhân bản, cân bằng tải và bộ nhớ đệm trong bộ nhớ có thể góp phần vào hiệu suất cơ sở dữ liệu hiệu quả.
Nếu một dịch vụ web được thiết kế để thực hiện nhiều truy vấn đọc và ghi vào cơ sở dữ liệu, thì bạn sẽ có nhiều phiên bản của cơ sở dữ liệu Postgres để xử lý các truy vấn ghi từ máy khách thông qua bộ cân bằng tải như pgpool-II trong khi- bộ nhớ đệm có thể được sử dụng để tối ưu hóa các truy vấn đọc.
Mặc dù pgpool-II có khả năng hoạt động như một bộ cân bằng bộ tải và bộ gộp kết nối, pgbouncer là giải pháp phần mềm trung gian được ưa thích để tổng hợp kết nối vì nó dễ thiết lập, không quá khó quản lý và chủ yếu hoạt động như một bộ gộp kết nối mà không có bất kỳ chức năng nào khác .




